目录:
Spark基础解析
SparkCore
SparkSql
SparkStreaming
第一章 Spark概述
Hadoop 与 Spark
2012年发布1.x稳定版:
HDFS(存储框架):一个 NameNode 对应 多个 DataNode、一个SecondaryNameNode
MapReduce(计算和资源调度框架): 一个JobTracker 对应 多个 TaskTracker
MR的缺点:
MR基于数据集的计算,所以面向数据
- 基本运算规则jobTracker从存储介质中获取(采集)数据,然后进行tasktracker计算,然后jobtracker将结果存储到介质中(每次job执行完数据要落盘),所以主要应用于一次性的计算,不适合数据挖掘和机器学习这样的迭代计算和图形挖掘计算。
- MR基于文件存储介质的操作,所以性能非常的慢。
- MR和Hadoop紧密耦合在一起,无法动态替换。
2013年10月 hadoop 2.x发布(Yarn):
将既负责资源调度又负责任务调度的jobTask从繁重的任务中解放,yarn将其职责分开。
ResourceManager 对应 多个NodeManager,负责资源调度;
Driver客户端 对应 多个Task,负责计算;
为了资源调度和任务调度还有计算解耦,在RM中存在ApplicationMaster,负责RM和Driver的交互,负责任务的调度;在NM中存在Container,负责NM和Task的交互。
降低资源框架和计算框架的耦合性,Driver和task关联,RM和NM关联。
Yarn将资源调度和计算分离,就使得将计算框架可插拔,替换成为可能。
Spark历史:
2013年6月发布
Spark基于Hadoop1.x架构思想,采用自己的方式改善Hadoop1.x中的问题
Spark计算基于内存(迭代计算中每个job之间数据是基于内存的,之间数据不落盘),并且基于Scala语法开发,所以天生适合迭代式(面向函数)计算
也是为了资源调度和计算解耦,Spark的基础架构中设计为Master和多个Worker相对应,负责资源调度;
在Master中也存在ApplicationMaster(更准确的说是其中的Driver),对应Worker中存在的Executor,负责计算;
整体设计和Yarn的设计思路很相似。为了使用Hadoop的HDFS存储框架,插拔计算框架,所以整体框架采用HDFS+Yarn+Spark.
定义
Spark是一种基于内存的快速、通用、可扩展的大数据分析引擎。
内置模块
Spark Core是框架中最重要的部分
Spark 中调度模块有Spark自己的独立调度器、Hadoop的Yarn和Apache的Mesos;上层的周边模块有SparkSQL、SparkStreaming、SparkMlib等
两个重要角色——针对计算而言
Driver(驱动器):管理、调度的
Executor(执行器):真正做计算的
第二章 Spark运行模式
执行WordCount
文件读入行(textFile(“input”))、扁平化(flatMap( _.split(“ “)))、转换结构( map ((_,1)))、分组聚合(reduceByKey(_+_))、收集展示(collect)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args : Array[String]): Unit = {
// 使用开发工具进行Spark WordCount的开发
//local模式
//创建SparkConf对象
//设定Spark计算框架的运行(部署)环境
//app id全局应用id
val config : SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//创建Spark上下文对象
val sc = new SparkContext(config)
//读取文件,将文件内容一行一行的读取出来
val lines: RDD[String] = sc.textFile("in")
//将一行一行的数据分解为一个一个的单词
val words: RDD[String] = lines.flatMap(_.split(" "))
//为了统计方便,将单词数据进行结构的转换
val wordToOne: RDD[(String, Int)] = words.map((_,1))
//对转换结构后的数据进行分组聚合
val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_+_)
//将统计结果采集后打印到控制台
val result: Array[(String, Int)] = wordToSum.collect()
//println(result)
result.foreach(println)
}
}
将Spark程序部署到Yarn中执行(重点)
两个框架协同工作,结合画图一起理解: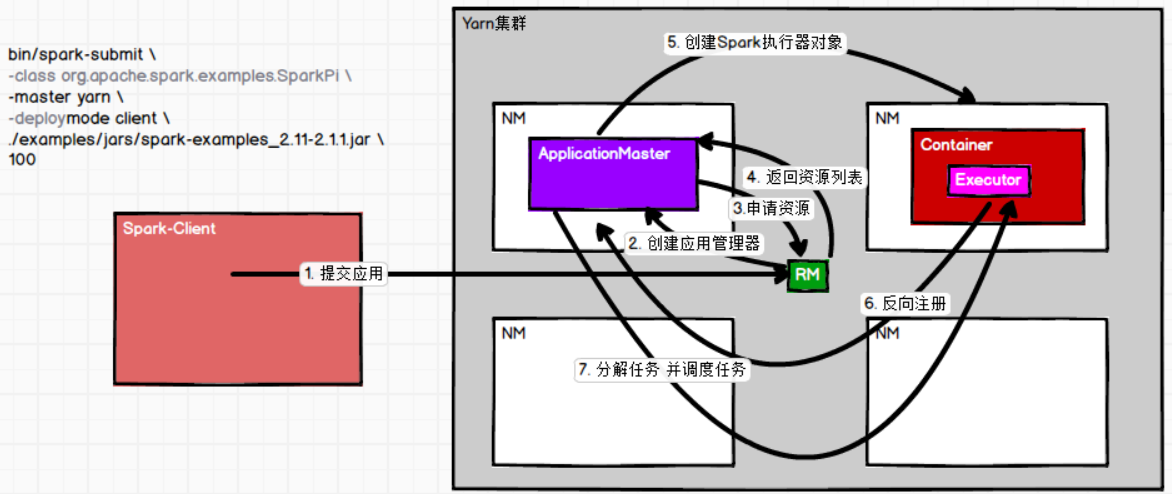
1.Client向RM提交app submit
2.RM选择一个NM启动AM,AM启动Driver(即初始化sc)
3.AM向RM申请资源
4.RM给AM返回可用的资源列表
5.AM在其余NM中创建Container对象,在Container中创建执行器对象Executor
6.NM的Executor向AM反向注册,汇报自己的存在
7.AM分解任务,并调度任务分发给不同的Executor执行
Spark部署到Yarn中执行spark-shell
在spark的目录下执行:bin/spark-shell --master yarn就可以在配置过spark-env.sh后以yarn模式运行
在终端输入yarn application -list可以看到在Yarn上运行的任务情况。

