目录
第一章 Zookeeper入门
第二章 Zookeeper安装
第三章 Zookeeper实战(开发重点)
第四章 Zookeeper内部原理
第五章 面试题(面试重点)
第一章 Zookeeper入门
zookeeper 是一个开源的分布式,为分布式应用提供协调服务的Apache项目。
Zookeeper = 文件系统 + 通知机制
ZK特点
1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群
2)集群中只要有半数以上节点存活,ZK集群就能正常工作(偶数时可能会出现脑裂风险)
3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。(给每次写操作都编序号Zxid)
5)数据更新原子性,一次数据更新要么成功,要么失败。(典型的事务特点)
6)实时性,在一定时间范围内,Client能读到最新数据。
数据结构
ZK数据模型结构整体上是一棵树,每个节点称ZNode。默认能够存储1MB的数据,每个ZNode通过其路径唯一标识。“不分文件和文件夹”
应用场景
统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。——JAva EE
“凡需要协调服务的地方都需要Zookeeper”
HA、Kafka、Hbase —— 大数据
第二章 Zookeeper安装
单例模式:解压、改名conf/zoo_sample.cfg为zoo.cfg,即可启动standalone单例模式。
启动ZK:bin/zkServer.sh start
查看ZK状态:bin/zkServer.sh status
停止ZK:bin/zkServer.sh stop
集群模式:
1.在单例的基础上,修改zoo.cfg中dataDir的值为自建的zkData地址。
2.添加集群中所有机器路径、通信端口号和选举端口号1
2
3server.1=hadoop101:2888:3888
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
3.之后在zkData中新建myid文件,添加对应的标号
4.修改bin目录下的zkEnv.sh文件,修改ZOO_LOG_DIR=/opt/module/zookeeper-3.4.10/logs目录;在开头配置JAVA_HOME为export JAVA_HOME=/opt/module/jdk1.8.0_144(为了防止远程执行命令丢失环境变量,就把环境变量写死。这步非必须。)
5.使用xsync分发脚本
第三章 Zookeeper实战(开发重点)
客户端命令行操作:(增删改查)
启动客户端:bin/zkCli.sh
命令基本语法 功能描述1
2
3
4
5
6
7
8
9
10
11
12
13
14help 显示所有操作命令
ls path [watch] 使用 ls 命令来查看当前znode中所包含的内容
watch表示观察这个结点变化,当该path发生改变时,会收到一次更改信息,之后更新不反馈。
ls2 path [watch] 查看当前节点数据并能看到更新次数等数据
create 普通创建
-s 含有序列(拼接全局序号)
-e 临时(重启或者超时消失)
get path [watch] 获得节点的值。
watch可以接收到一次set命令导致的结点变化信息。
set 设置节点的具体值
stat 查看节点状态
delete 删除节点
rmr 递归删除节点
quit 退出客户端
第四章 Zookeeper内部原理
4.1 节点类型
四种:持久非顺序编号节点、临时非顺序编号节点、持久顺序编号节点、临时顺序编号节点
4.2 Stat结构体
1 | 1)czxid-创建节点的事务zxid |
4.3 监听器原理(面试重点)
new Zookeeper时生成两个线程:SendThread 和 EventThread。
SendThread负责连接通信,所有注册请求都通过它异步发给服务端
EventThread负责监听变化,启动回调函数Watcher中的process()方法
大致原理:
ZooKeeper对于每个ZNode都有一个WatcherList,所有想要观察的这个ZNode的其他ZNode都注册在WatchList中。如果被观察的ZNode发生变化,线程就从上到下遍历这个List,遍历一个划掉一个。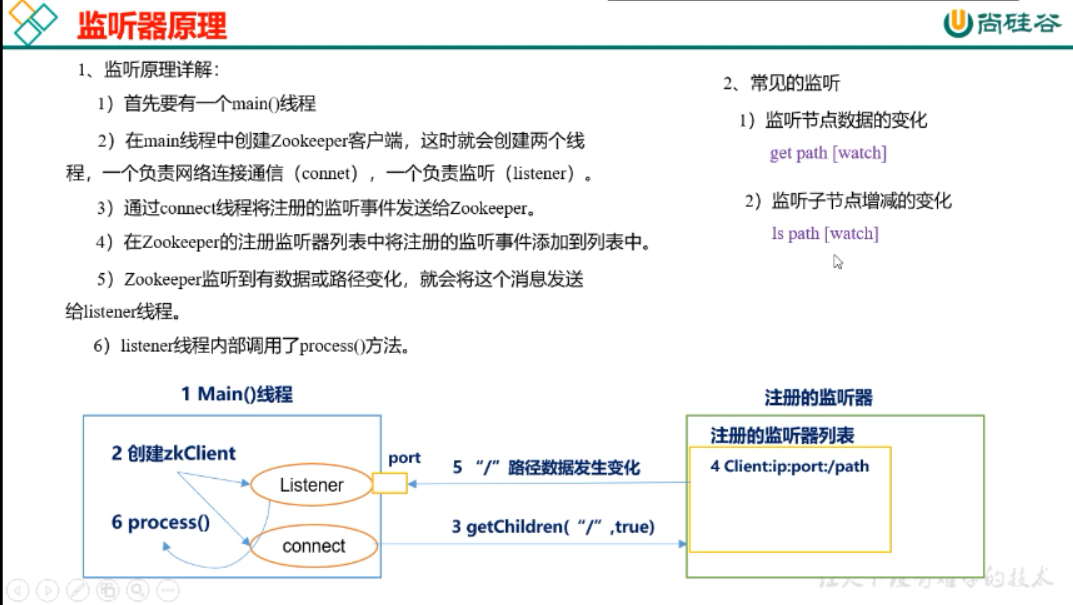
ZAB(Zookeeper atomic broadcast)协议:(最重要内容)
一句话概括:保证Zk数据全局一致,保证读写顺序的原理。
“没有Leader选Leader,有Leader就干活”—— 崩溃恢复 和 正常读写
在以上两个阶段不断切换
4.5 选举机制(面试重点)
选举时比较(二次比较):先比较zxid,再比较myid。(尽量选择最新的节点做Leader)过半数以上同意节点当选leader.
5个ZNode时,若一个一个起服务,则3号当选;若一起开启服务,则最大的5号当选。
类似议会中议长和议员的关系。
4.6 写数据流程
客户端将写请求发送给任意一个server,然后这个server向leader汇报信息,leader向集群中所有server发送投票申请,过半同意后leader再广播给所有server写请求。
一开始发送投票申请时,写请求进每个节点的代写队列list。投票成功了就写,失败了就划掉回滚。
在过半数投票同意时,集群会执行写请求,原先投反对票的节点认为自己有问题进而自杀,同时从leader处同步数据。由此可以保证集群数据唯一性
同意与否的依据就是判断请求的编号zxid和代写队列list中最小的编号相比,如果请求编号更大,表示请求时间更新,所以同意。失败的情况更多出现在各别节点的网络情况出现问题编号出现问题。
集群中observer就类似议会机制下的普通群众,不参与选举。由leader和follower选举后执行成功和失败的操作。
出现observer的两种常见情况:1.集群规模很大;2.集群跨数据中心DC

